I feel that BeeHive has been the most important Open Source project I have been involved so far. Not because it is my latest project, but because I feel the potential is huge.
The infoq article that came out on Monday is pretty much a theoretical braindump on the Reactor Actor Model. I had expected this to stir up so much controversy as the claims I am making are pretty big - this has not happened yet. Maybe the text does not flow well or it is just early. In any case, the idea is clear: sticking to Processor Actors and build a web of loosely connected events to fulfil a system's business requirement while maintaining fluid evolvability. However, I fear the article was perhaps too dry and long and did not fully demonstrate the potential.
Hence I have set out to start a series on BeeHive and show the idea in some tangible scenarios "Show me the codz" - with the code easily accessible from GitHub. So now let's roll on.
BeeHive
BeeHive makes it ridiculously simple (and not necessarily easy) to build decoupled actors that together achieve a business goal. By using topic-based subscription, you can easily add actors that feed on an existing event and do something extra.Here we will build such systems will a few lines of code. You can find the full solution in the samples folder in the source. The code below is mainly is a snippet (e.g does not have the Dispose() methods for removing clutter).
Scenario 1: News Feed Keyword Notification
Let's imagine you are interested in to know all breaking news from one or several news feeds and would like to be notified when a certain keyword occurs in the news. In this case we design a series of reactive actors that achieve this while allowing for other functionality to be built on top of existing topic based queues. We use Windows Azure for this example. In order to achieve this we need to regularly (e.g. every 5 minutes), check the news feed (RSS, ATOM, etc) and examine new items arrived and look for the interested keyword(s) and then perhaps tweet, send email or SMS text.Pulsers: Activities on regular intervals
BeeHive works on a reactive event-based model. Instead of building components that regularly do some work, we can have generic components that regularly fire an event. These events then can be subscribed to by one or more actors to fire off the processing by a chain of decoupled actors.BeeHive Pulsers do exactly that. On regular intervals, they are woken up to fire off their events. Simplest of pulsers, are assembly attribute ones:
[assembly: SimpleAutoPulserDescription("NewsPulse", 5 * 60)]NewsPulse with empty body.Dissemination from a list: Fan-out pattern
Next we set up an actor to look up a list of feeds (one per each line) and send an event per each feed. We have stored this list in a blob storage which is abstracted asIKeyValueStore in BeeHive.[ActorDescription("NewsPulse-Capture")]
public class NewsPulseActor : IProcessorActor
{
private IKeyValueStore _keyValueStore;
public NewsPulseActor(IKeyValueStore keyValueStore)
{
_keyValueStore = _keyValueStore;
}
public async Task<IEnumerable<Event>> ProcessAsync(Event evnt)
{
var events = new List<Event>();
var blob = await _keyValueStore.GetAsync("newsFeeds.txt");
var reader = new StreamReader(blob.Body);
string line = string.Empty;
while ((line = reader.ReadLine())!=null)
{
if (!string.IsNullOrEmpty(line))
{
events.Add(new Event(new NewsFeedPulsed(){Url = line}));
}
}
return events;
}
}
ActorDescription attribute used above signifies that the actor will receive its events from the Capture subscription of the NewsPulse topic. We will be setting up all topics later using a single line of code.So we are publishing
NewsFeedPulsed event for each news feed. When we construct an Event object using the typed event instance, EventType and QueueName will be set to the type of the object passed - which is the preferred approach for consistency.Feed Capture: another Fan-out
Now we will be consuming these events in the next actor in the chain.NewsFeedPulseActor will subscribe to NewsFeedPulsed event and will use the URL to get the lastest RSS feed and look for latest news. To prevent from duplicate notifications, we need to know what was the most recent tem we checked last time. We will store this offset in a storage. For this use case, we choose ICollectionStore<T> which its Azure implementation uses Azure Table Storage.[ActorDescription("NewsFeedPulsed-Capture")]
public class NewsFeedPulseActor : IProcessorActor
{
private ICollectionStore<FeedChannel> _channelStore;
public NewsFeedPulseActor(ICollectionStore<FeedChannel> channelStore)
{
_channelStore = channelStore;
}
public async Task<IEnumerable<Event>> ProcessAsync(Event evnt)
{
var newsFeedPulsed = evnt.GetBody<NewsFeedPulsed>();
var client = new HttpClient();
var stream = await client.GetStreamAsync(newsFeedPulsed.Url);
var feedChannel = new FeedChannel(newsFeedPulsed.Url);
var feed = SyndicationFeed.Load(XmlReader.Create(stream));
var offset = DateTimeOffset.MinValue;
if (await _channelStore.ExistsAsync(feedChannel.Id))
{
feedChannel = await _channelStore.GetAsync(feedChannel.Id);
offset = feedChannel.LastOffset;
}
feedChannel.LastOffset = feed.Items.Max(x => x.PublishDate);
await _channelStore.UpsertAsync(feedChannel);
return feed.Items.OrderByDescending(x => x.PublishDate)
.TakeWhile(y => offset < y.PublishDate)
.Select(z => new Event(new NewsItemCaptured(){Item = z}));
}
}
}
Here we read the URL from the event and capture the RSS and then get the last offset from the strorage. We then send the captured feed items back as events for whoever is interested. At the end, we set the offset.Keyword filtering and Notification
At this stage we need to subscribe toNewsItemCaptured and check the content for specific keywords. This is only one potential subscription out of many. For example one actor could be subscribing to the event to store these for further retrieval, another to process for trend analysis, etc.So for the sake of simplicity, let's hardcode the keyword (in this case "Ukraine") but it could have been equally loaded from a storage or a file - as we did with the list of feeds.
[ActorDescription("NewsItemCaptured-KeywordCheck")]
public class NewsItemKeywordActor : IProcessorActor
{
private const string Keyword = "Ukraine";
public async Task<IEnumerable<Event>> ProcessAsync(Event evnt)
{
var newsItemCaptured = evnt.GetBody<NewsItemCaptured>();
if (newsItemCaptured.Item.Title.Text.ToLower()
.IndexOf(Keyword.ToLower()) >= 0)
{
return new Event[]
{
new Event(new NewsItemContainingKeywordIentified()
{
Item = newsItemCaptured.Item,
Keyword = Keyword
}),
};
}
return new Event[0];
}
}
Now we can have several actors listening for NewsItemContainingKeywordIentified and send different notifications, here we implement a simple Trace-based one:[ActorDescription("NewsItemContainingKeywordIentified-TraceNotification")]
public class TraceNotificationActor : IProcessorActor
{
public async Task<IEnumerable<Event>> ProcessAsync(Event evnt)
{
var keywordIentified = evnt.GetBody<NewsItemContainingKeywordIentified>();
Trace.TraceInformation("Found {0} in {1}",
keywordIentified.Keyword, keywordIentified.Item.Links[0].Uri);
return new Event[0];
}
}
Setting up the worker role
If you have an Azure account, you need a storage account, Azure Service Bus and a worker role (even an Extra Small instance would suffice). If not, you can use development emulators although for the Service Bus you need to use Service Bus for windows. Just bear in mind, with local emulators and Service Bus for Windows, you have to use special versions of Azure SDK - latest versions usually do not work.We can get a list of assembly pulsers by the code below:
_pulsers = Pulsers.FromAssembly(Assembly.GetExecutingAssembly())
.ToList()
Also we need to create an
Orchestartor to set up factory actors. We need to call SetupAsync() to set up all the topics and subscriptions.Also we need to register our classes against Dependency Injection framework.
Now we are ready!
After running the application in debug mode, here is what you see in the output window:
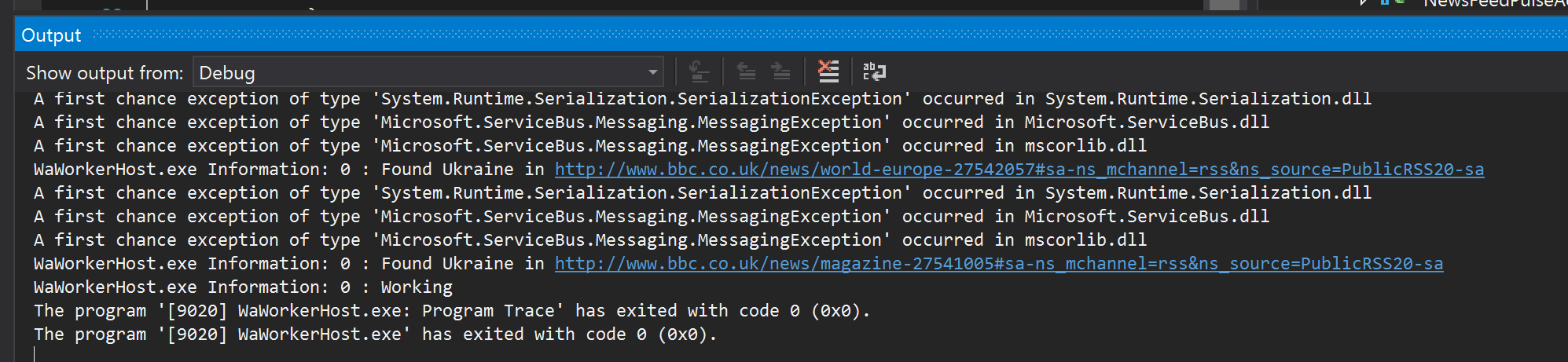

And this one:

In the next post, we will discuss another scenario.